API Caching: Techniques for Better Performance

Pieces is your AI companion that captures live context from browsers to IDEs and collaboration tools, manages snippets and supports multiple LLMs - all while processing data locally for maximum control.
Improving the performance of APIs involves a broad set of strategies. These include avoiding redundancy, optimizing database queries, pagination, compression, rate limiting, asynchronous logging, efficient request methods, connection pooling, data mesh and pipelines, branching strategies, and more. Among these techniques, API caching stands out as a powerful way to increase speed and scalability.
API caching entails temporarily storing frequently needed data or responses to ensure they are retrieved swiftly upon request. In turn, the API reduces response times, enhances overall performance, and increases scalability. You can set up caching in their applications with the proper tooling and expertise. This helps reduce the cost of your backend and allows you to use cached data as a fallback in cases of network failure or errors in the API. However, poor implementation and testing lead to unmanageable loads, which could break an application.
In this article, we will dive into API caching. We will explain how caching works, explore implementation techniques, and spotlight the best practices and challenges involved. Before closing out, we will examine a few case studies on successful and failed caching. Lastly, we’ll look into API caching tools to put it all together.
Understanding API Caching Basics
Caching strategies involve storing copies of repeatedly accessed data at several points along the request-response path, known as a cache. When an API call is made with similar parameters, the system retrieves the response from the cache and does not need to make a trip to the server, nor does it have to repeat the same operations to deliver the same result. This reduces latency in API calls and overall load on the server.
Often, cached information includes response data, which could be weather, finance, or news data, and metadata, which carries information about data in the cache, such as its validity time and when it was last updated. Metadata is used in handling expiration, a process that clears stale data from the cache. Expiration can be triggered after some period of time or following certain events, like data updates. For example, a stock reporting app might cache stock prices until new prices are set.
Caching can be classified into three categories: client cache on the browser level, server cache, and a hybrid approach combining the client and server. It is also worth noting that in REST APIs, the most common implementation (even cloud APIs use REST), only the GET and POST methods are cacheable.
API Caching Techniques
Here is a detailed breakdown of the available caching techniques.
Client-Side Caching
Client-side caching happens on the user’s device, typically the browser or a mobile application. Often, static assets or content are stored, including images, CSS files, JavaScript files, and API responses that rarely change. The cached files are stored in local storage, cache storage, IndexedDB, session storage, or cookies based on the data type. By eradicating the need to fetch data from the API, the application consuming the API loads faster, giving a better user experience. This technique has additional benefits, such as decreased network traffic and offline access, which powers the application in the case of network failures.
To implement the client-side cache, you must set specific HTTP headers in API responses and direct the client on how and when to cache responses. The most common headers are cache-control, expires, e-tags, and last-modified. Let’s see using examples.
Cache-control addresses caching directives for clients and intermediaries, with the most common ones being:
public — Responses are cacheable by any cache, including proxies, content delivery networks, and browsers.
private — Responses can only be cached by the browser. This option is suitable for user-specific data, such as a personalized dashboard or sensitive information.
no-cache — Responses must be validated before using cached copies.
no-store — Responses shouldn’t be cached.
max-age — The available time, counted in seconds, up to which the response is cacheable.
This method applies to both API request caching and API response caching. Here’s an example in Node.js using the Express framework. In this example, the cache is specified to be accessible by the browser only and valid for up to an hour.
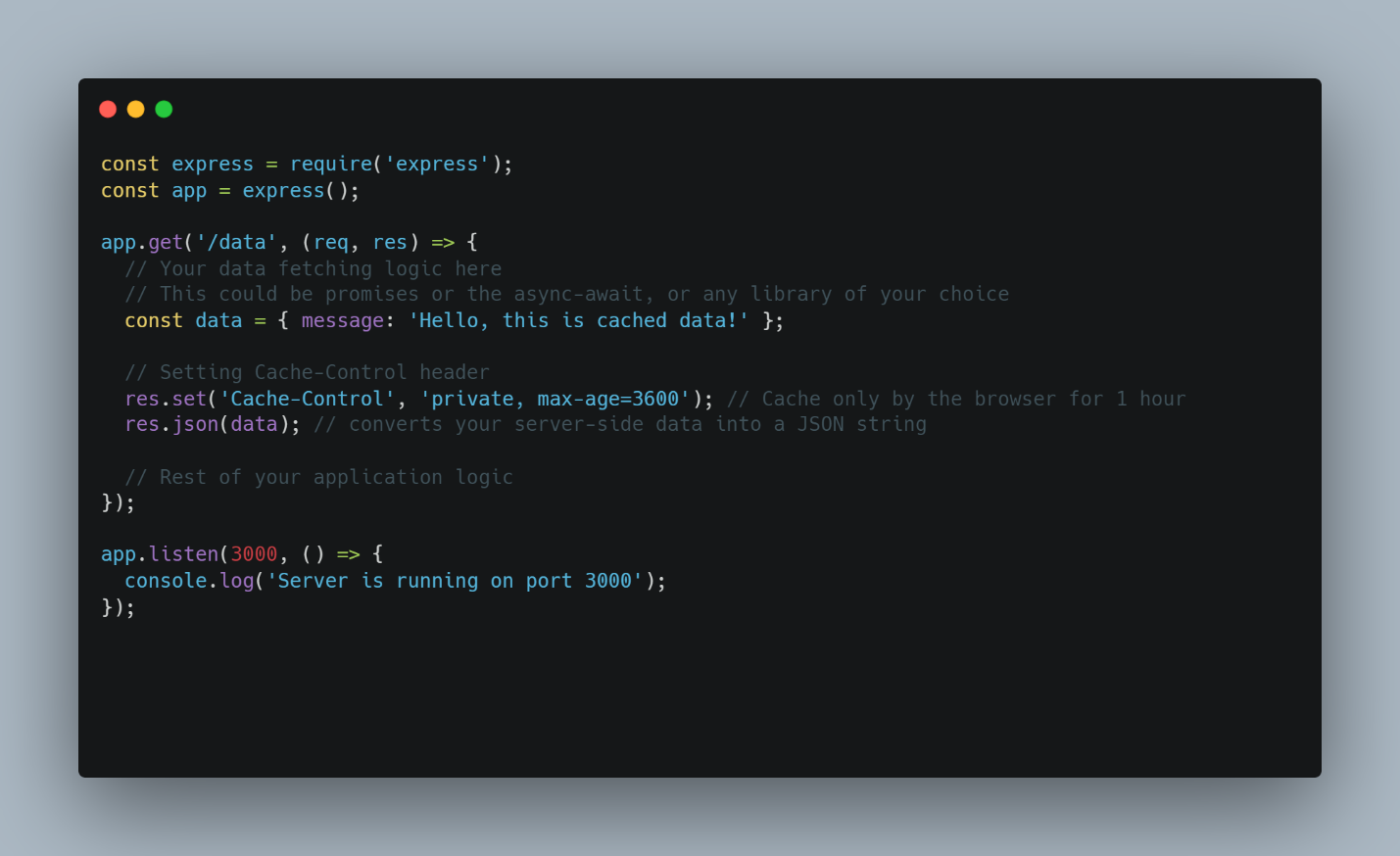
Expires is another alternative to cache-control that can provide an HTTP date timestamp, after which the cache is considered stale. It can also be used alongside the cache-control header. In the example below, the expires acts as a fallback for older browsers (HTTP/1.0 clients) that do not understand the cache-control header.
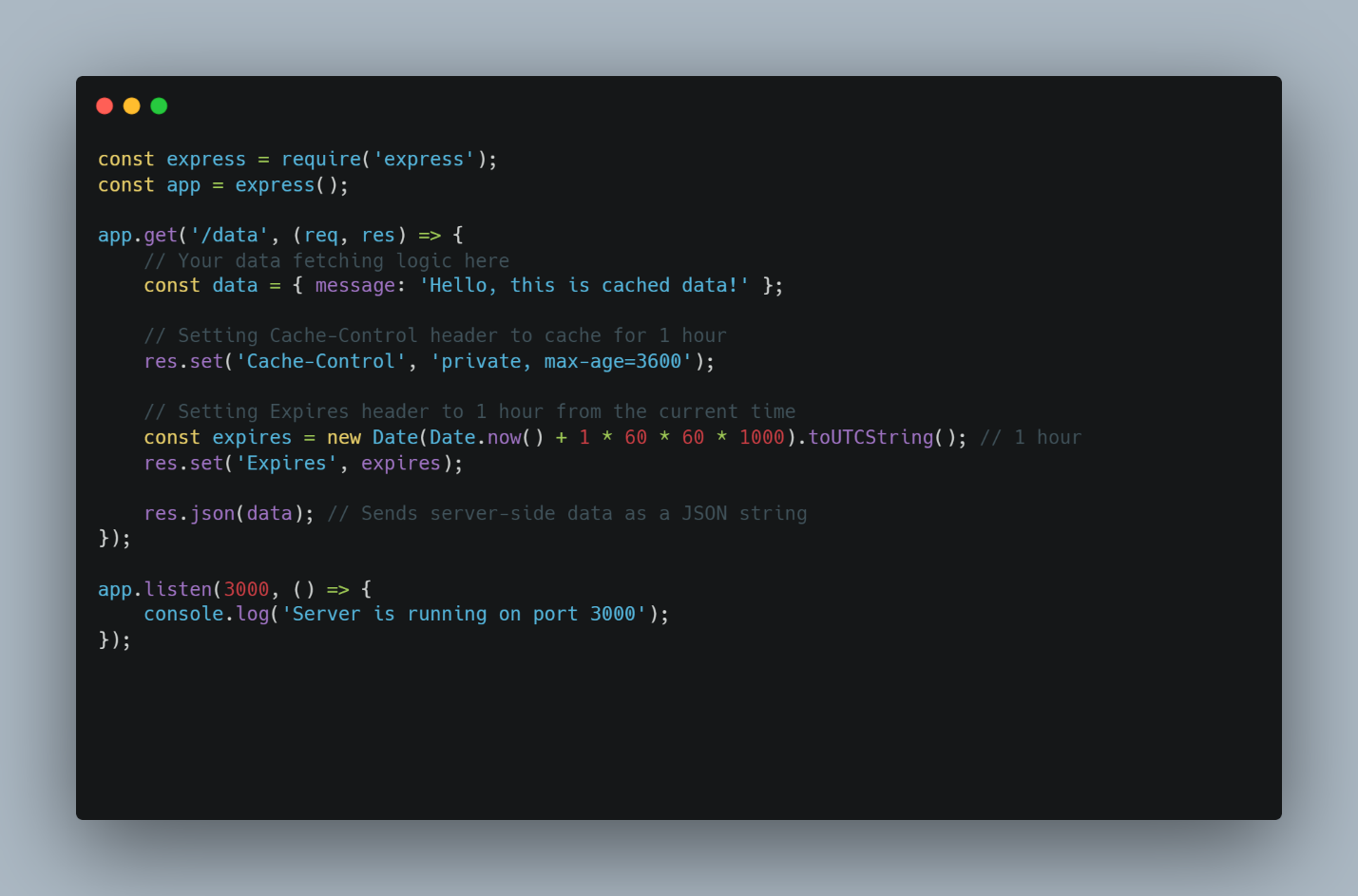
The ETag header is used to identify a particular resource type. When the resource changes in the server, the ETag value should also change. This method is particularly helpful when handling large static resources such as photos, video, and large JSON files. A trip to the server without returning modified files saves network bandwidth and load time. For high-frequency small requests, this option might not have significant changes; you can serve resources directly from the cache. In the example below, we use the if-none-match header to check whether the cached resource is still valid.
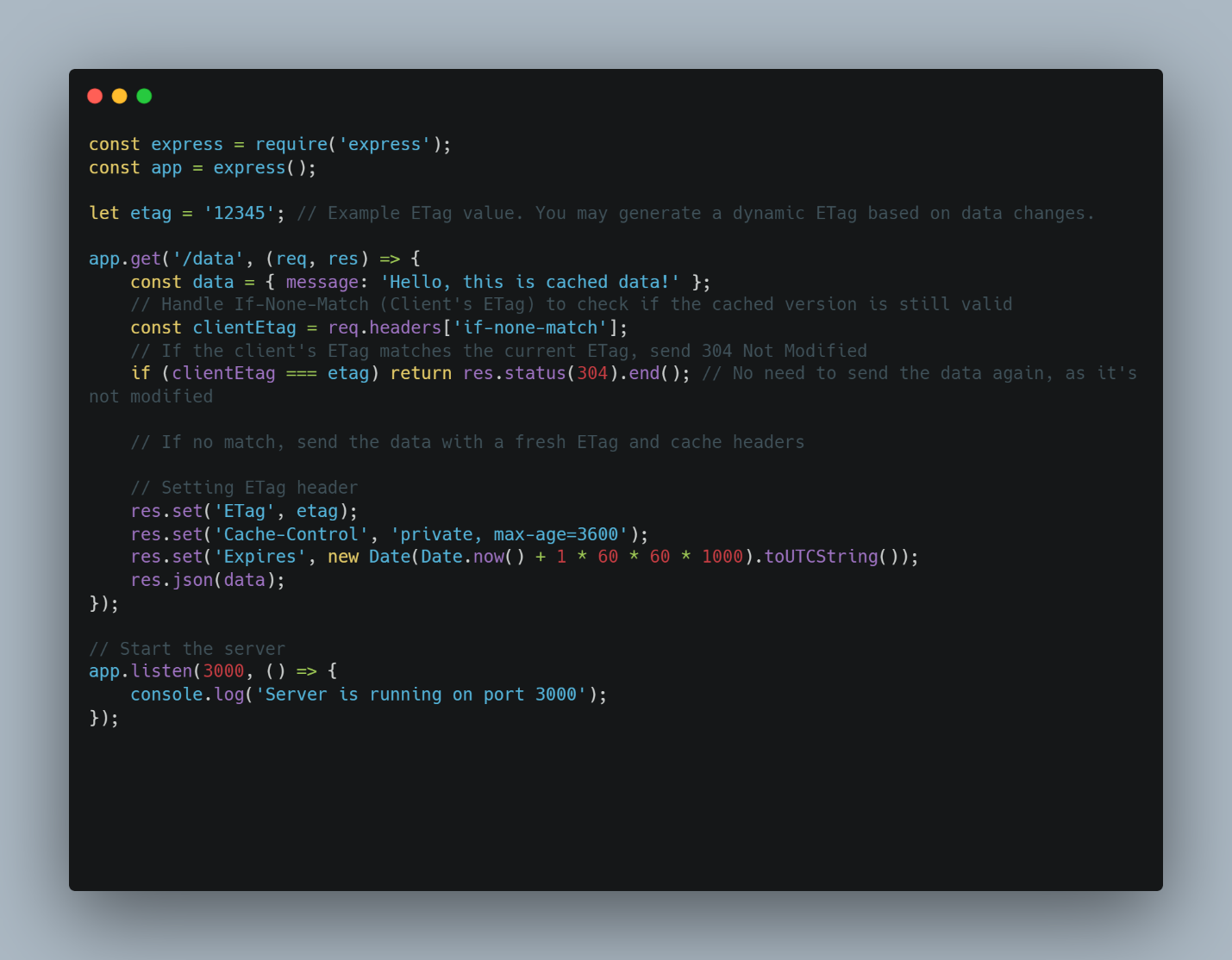
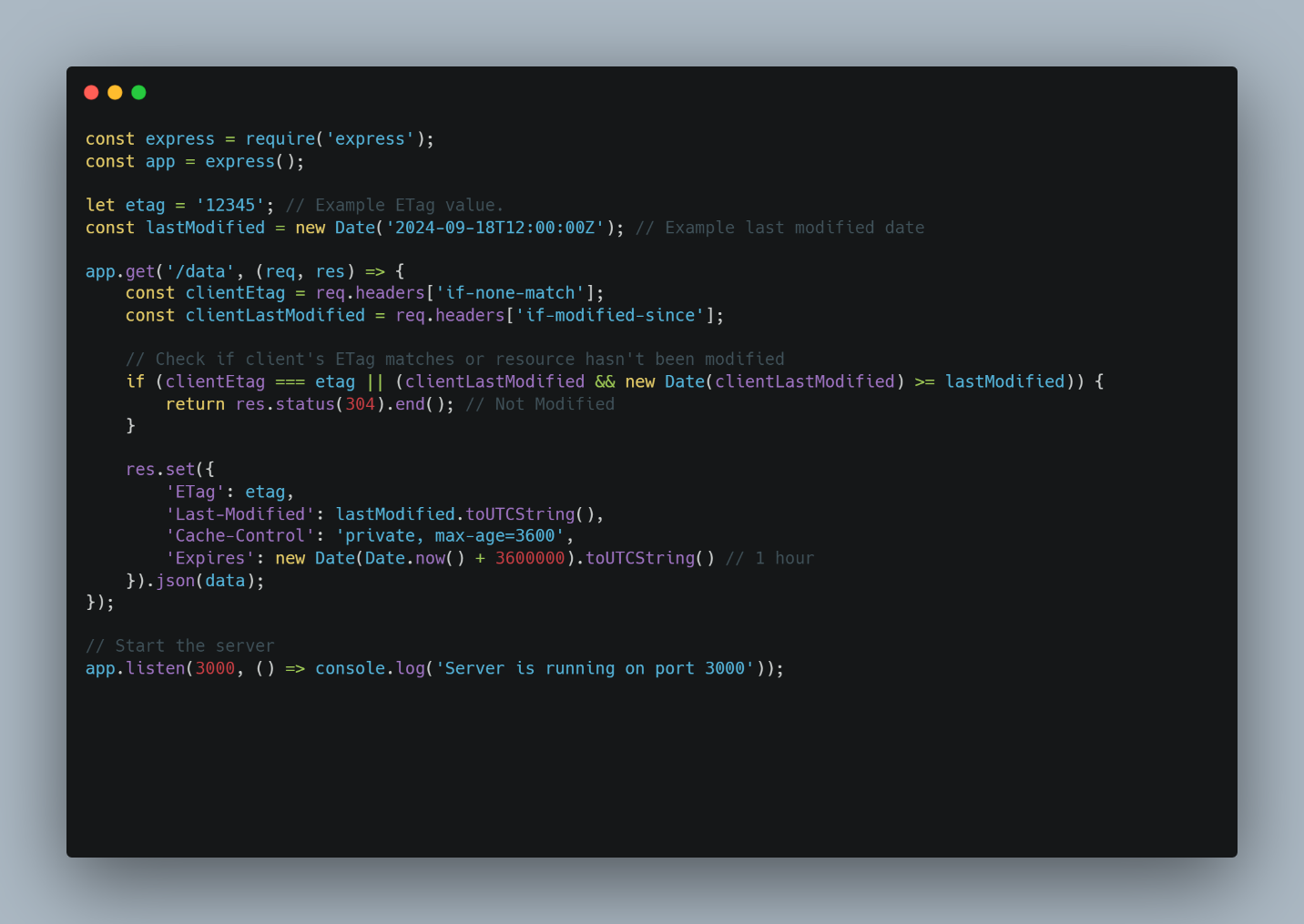
The last-Modified header works well with the if-modified-since to check if the copy is valid by comparing the two values. Here’s an example of how we combine it with the ETag header in practice.
Server-Side Caching
In this method, the cached data is stored on the server once a user makes an API request. On subsequent requests, resources are served from the server, and there’s no need to pull data from the database — this saves time. A good instance to implement this technique is dynamic content generated from the backend and can be shared across multiple users. This, in effect, could be news feeds or product data catalogs. Or alternatively, API responses that are expensive to generate. It is also suitable for handling a large number of requests effectively. There are two methods available here: memory and disk caching.
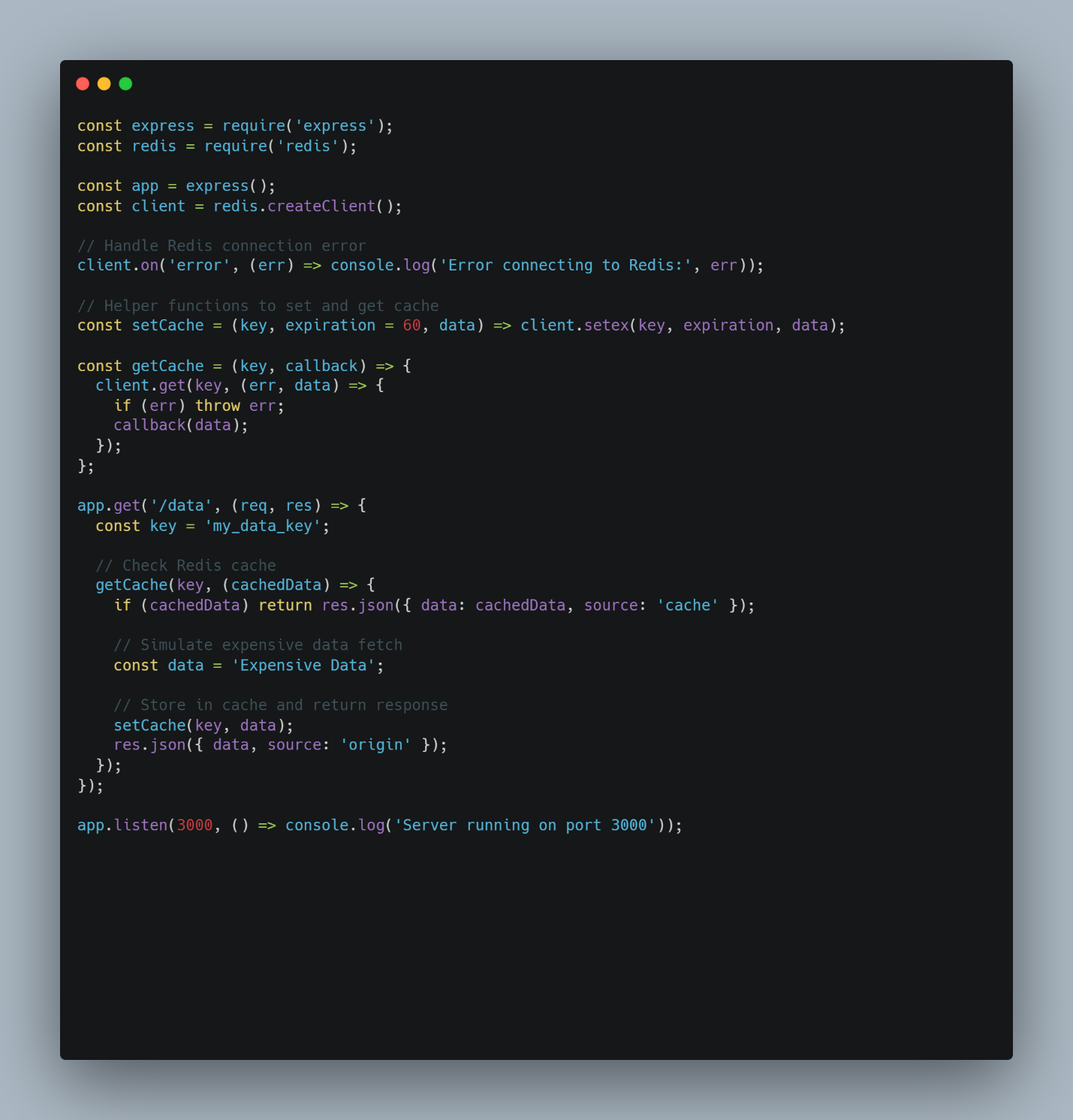
In-memory caching can be used for quick lookups. It stores data in volatile memory. In this case, data is lost if the server is restarted unless you use a caching tool like Redis in persistence mode. Choose this option for frequently accessed non-critical data where speed is a high priority. For a simple implementation, the Node Cache is a good option. Here’s an example implementation using Redis.
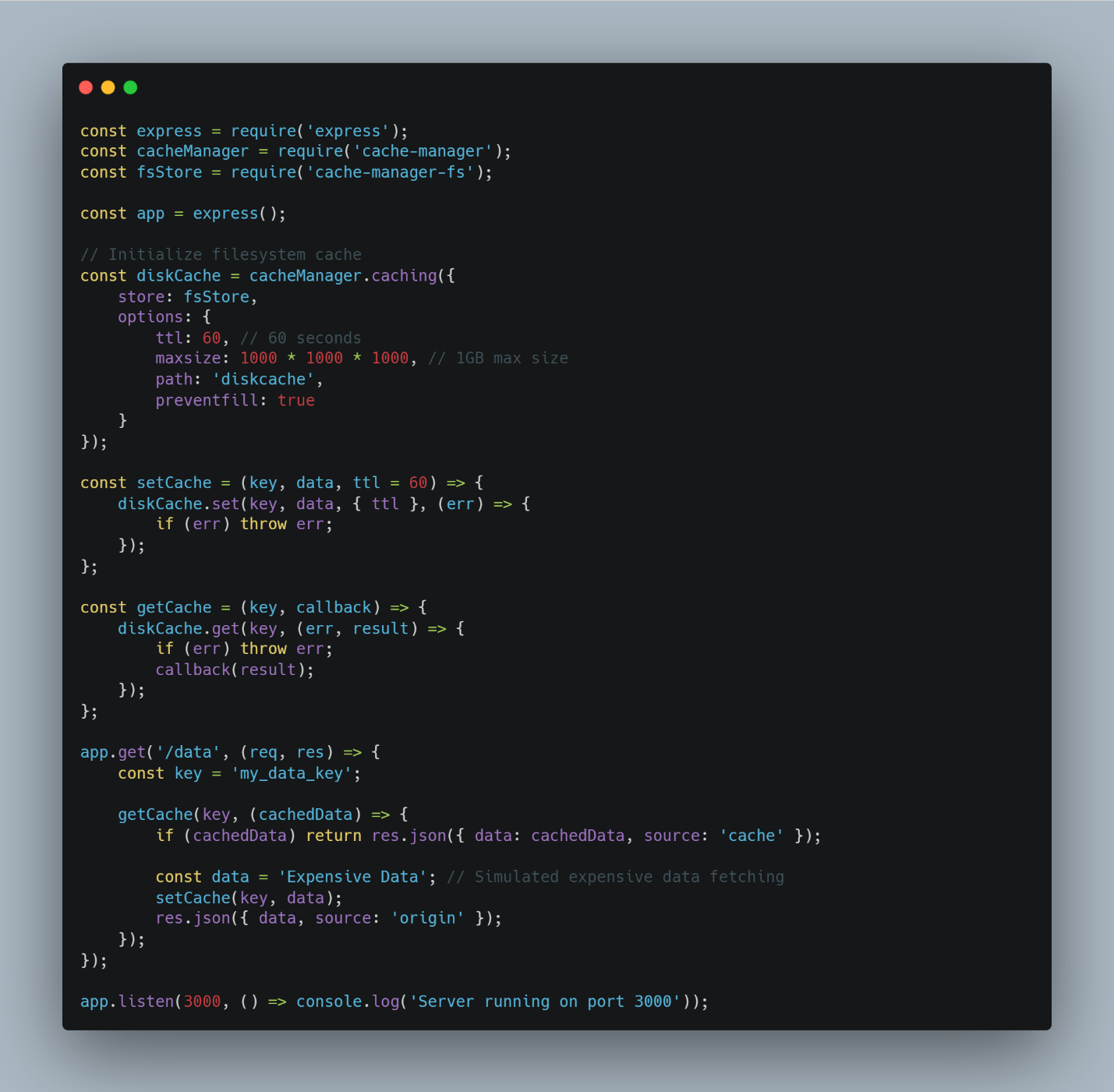
For more persistence beyond server restart, you can opt for disk caching, although it is slower than memory caching. Here’s an example:
Best Practices for Effective API Caching
While caching is a good solution for efficiently serving data for both the server and client, it may not reduce the cost of data if not properly implemented. The best practices around software development will always be subjective, and the implementation specifics will depend on the problem you’re solving at hand. However, a holistic view of the general approach will help you implement a useful and accurate caching workflow.
Consider the Cost
In the context of resources, it is meaningful to consider the cost of deploying caching mechanisms on both the server and client. Every cache instance requires some storage where the content is loaded. This storage is, therefore, not usable or available to other processes and functions. Because cached content is spread across APIs, providers, and microservices, even small amounts of data could consume large chunks of memory. For static assets, this may not be an issue. Still, in the case of dynamic content being moved into and out of the cache, along with maintaining the accuracy of the data, this could get extremely expensive. Similar to considering the time/space complexities when writing algorithms, evaluate what data needs to be cached and examine its impact in extreme cases.
Allocate Cache to Fit
Just like the choice of data to cache, storage, whether client or server, is worth considering. Occasionally, a hybrid approach would work. This reduces the cost for both parties, but that comes at the price of more overhead to the system and increased complexity. On the client side, storing user data often referenced locally would be better to reduce additional calls and boost the server with fewer requests. Should you store a cache on the server, the API isn’t burdened in the time of repeated calls as no processing is done, no transformation and manipulation is done, and the wait time is reduced, although an API call has to be made.
Security Considerations
When you cache, remember that privacy and security are essential for both users and the codebase alike. Not all data needs to be cached. If poorly done, it could lead to major issues. For example, caching admin credentials on the server could lead to breakage on clients. These credentials, in turn, could be used to attack the server. If that sounds like a simple case, consider the event where an application pushes API tokens into the cache and then collects error reports, which could be used to expose the service architecture. This decreases the overall system safety and security.
Additionally, security and accuracy can intertwine. For example, in an API handling customer data, if the whereabouts of where the information is out of date or incorrect, the application gets exposed. It also breaks the clients' reliance on the data. Such a scenario either leads to clients having no order data if their application doesn’t break or the service deliverer seemingly gets that there are no customers. In short, if you are not careful, cache constraints could partially or wholly eliminate some interactions.
Set Rules as per Complexity and Usefulness
Many issues revolving around cache are about content, with the biggest debate being what is cacheable versus what isn’t. This not only depends on who owns the cache but also on the intent of cached data. For example, consider a hybrid caching approach. Locally cached resources could hold information on requests, and the server cache could serve HTML, CSS, and some scripts for the service. Of course, this could also depend on whether you are using client-side rendering (CSR) or server-side rendering (SSR) when providing the user interface. This is only a simple use case.
Things quickly become complex when handling dynamic content over a long period. In such scenarios, the API status is worth considering. While uncommon, the state can be cached when the API is down or undergoing updates. Passwords should never be cached on the server, and server mappings (data locations beyond public endpoints) must never be available to the client. Should you have any assumptions when writing cache workflows, testing, validating, and rejecting if the need arises is essential. At scale, you should establish rules that protect cached data. As a practice, this builds a solid framework for you to audit your cache.
Audit Your Cache
Modern software development involves shipping quickly. An ever-evolving codebase requires frequent reviews of the caching strategies, assumptions, and implementations. Caching non-existent content leads to more overhead, even if no data is stored. A good example is where a microservice caches shipping order status. To reduce the cost, a developer may purchase a subscription to an external API provided by product shippers to query the status. In the first workflow, the system checks the cache, tests the status by running checks across a status table, and returns the state to the customer. In the new approach, the external API picks the data and sends it to the customer, where it is cached. The codebase is complex if the status table and the code around it still exist. Although you can still call the endpoints, their data isn’t needed. There’s no way to tell that the data is no longer useful. If the data is removed, it remains active until some arbitrary termination happens. With a growing order list, this is an additional operational cost with no value contributions to the application.
Challenges and Considerations
Even armed with technical skills and the best cache implementation practices, API caching is not without its challenges.
Cache Misses and Their Impact
A cache miss is when data requested by a processor or software component is not found in the cached memory. When there's a miss, data must be fetched from the main memory or a lower-level cache instance. In high-speed operation systems, this delay could introduce a performance bottleneck. The rate at which misses occur depends on the size of the cache, the organization of data in the cache, replacement policies, and the model by which data access patterns are implemented. Digging into the issues that could cause a cache miss is good for evaluating performance. Also, not all misses have an impact; for example, the first instance of access to a block of data is unavoidable.
Distributed Caching
Distributed applications have a way to implement caching, which can be either shared or private. If private is the implemented method, the data is held locally on the application instance (typically the client) in a memory store or a local file system. The size of the cache is constrained to the device running the application and the amount of memory running the application.
Each app has its cache snapshot for multiple instances running the same application. The data is consistent if the system is built on a shared cache. This model emulates the in-memory caching. An advantage of using a shared cache is that it allows for scalability using clusters like those offered by Kubernetes. The downside is that shared cache is slower and introduces complexity when separating the cache on serving applications.
Trade-offs in Caching
When looking at hardware caches for CPU memory systems, there are many items to consider. The available area, which translates to the amount of data stored in the cache memory, is important; bigger means slower. The line size: How much data needs to be fetched? Most caches these days are around 64 bytes.
Associativity, or the number of places in the cache where an address can be stored. Often, this tends to be 8 or 16-way associative. Ports also matter, as they impact how many reads and writes can be performed in a single cycle. Also, is there support for unaligned operations? For instance, some caches will support stores and loads that cross cache line boundaries without a penalty, while others will not.
When Not to Use Caching
Here are instances when you should avoid caching:
If an external cache adds latency to the application
If an external cache is an additional cost
If an external cache decreases availability
If the cache introduces too much complexity in the application
If an external cache ruins database caching
If an external cache introduces vulnerabilities and security issues
Case Studies and Examples
Examining extreme cases, both successes and failures, is important when conducting a case study on applying a programming technique. We’ll spotlight the two ends to give a clear picture.
ByteByteGo is an excellent example of scaling to 1.2 billion daily API requests. Their caching strategy begins with three goals: reducing latency on their systems, keeping cache servers warm and running to offload backend systems, and maintaining data consistency. These aims are key to building a reliable solution, but a robust one must include observability, monitoring, optimization, and automated scaling. To achieve low latency, the cache client maintains open connections to cache servers. Rather than establishing new connections, an incoming request borrows a connection from the established pool. Adopting a fast failure approach also prioritizes the system's stability over failure.
To keep cache servers warm and running, they planned for failure through mirrored and guttered pools. In sync with the primary pool, mirror pools take over reads if the primary one fails. For temporary failures, the gutter pool, which is small and empty, caches values with a short time-to-live (TTL) until the primary pool recovers. Additionally, they also use dedicated servers for specific use cases. For keys frequently accessed more than others, splitting them across multiple servers reduces the concentration on one server as it could get overloaded.
For data consistency, ByteByteGo tracks failures and writes consistent CRUD applications. Tracked failures are then duplicated and used to invalidate cache keys. In CRUD apps, the data is fetched from the cache; if missed, it is sourced from the primary store. For updates, they use a short TTL to update the primary store, then the cache to keep data consistent and invalidate stale data quickly. A similar strategy is used for deletion through short TTLs while creations are directed to the primary store where unique data IDs are used.
Twitter has had a decade of failure incidents, with the reports directly pointing toward caching.
In this report by Dan Luu, a senior engineer who has worked at Google, Microsoft, and even Twitter, we gather that cache failures have stemmed from anomalies that trigger positive feedback loops, leading to runaway failures.
Others have come not from logical errors in the code handling cache but the interaction of system components such as hardware or incomplete fixes from previous incidents. The many incidents include cache inconsistency due to independent routing decisions and packet loss due to interrupt requests (IRQ) overloads and BIOS issues, power loss which caused cache failures due to missing directories, high profile tweets that led to aggressive client entries, and load spikes, among others.
From these incidents, it is clear that fixes involved improved monitoring and logging, enhanced architectural changes to make cache systems resilient to overloads, adjusting configurations to limit TCP buffer sizes, hardware and software updates to cater to BIOS, Kernel fixes, and upgrades to network interfaces.
The development team was also forced to improve processes such as better deployment practices and more realistic load testing. In addition to these, we can draw a few lessons from the failure and fixes. There is a need for consistent hardware settings and proactive testing for failure nodes. It is also a good practice to have more visibility and to understand operating cache systems. As a rule of thumb, proper configuration and well-thought-out architectural designs will prevent cache-related downtimes.
Tools and Technologies for API Caching
Here are some open-source applications and tools to implement server-side caching at the enterprise level on Linux.
Redis — Remote Dictionary Server is a free, flexible, and high-performance distributed in-memory system that works with most programming languages. It supports numerous data structures such as hashes, strings, lists, sets, streams, sorted sets, bitmaps, and more. Redis applies to many problems, including database caching, public messaging systems, API responses, and queues. This makes it applicable across gaming, social network applications, real-time data analytics, RSS feeds, user recommendations, etc.
Memcached — Free and well-known for its simplicity, Memcached is a distributed and powerful memory object caching system. It uses key-value pairs to store small data chunks from database calls, API calls, and page rendering. It is available on Windows. Strings are the only supported data type. Its client-server architecture distributes the cache logic, with half of the logic implemented on the server and the other on the client side.
Apache Ignite — Free and open-source, Apache Ignite is a horizontally scalable key-value cache store system with a robust multi-model database that powers APIs to compute distributed data. Ignite provides a security system that can authenticate users' credentials on the server. It can also be used for system workload acceleration, real-time data processing, analytics, and as a graph-centric programming model.
Couchbase Server — An open-source, NoSQL distributed database that stores data as key-value pairs. It is available on Linux, Windows, and MacOS. In addition to API management caching, Couchbase offers a power query engine, purpose-built indexers, big data integration, high availability, and full-stack security. It also provides native cluster support for multiple instances. This server can be used for large interactive mobile, web, and IoT applications.
Hazelcast IMDG — A fast, lightweight, extensible data grid middleware for in-memory computing. It supports many language-native data structures such as lists, sets, maps, RingBuffer, HyperLogLog, and Multimap. Besides cluster support, Hazelcast gives you an API collection to access the CPUs for maximum speeds and security-enhancing features such as client authentication and authorization through Java Authentication and Authorization Service (JAAS).
Mcrouter — Developed and maintained by Meta (Facebook), Mcrouter is a deployment scaling tool that can run multi-level caches, support multi-clusters, and provide flexible routing, hashing tools, connection pooling tools, and monitoring tools. It also provides additional services like debugging, cache warm-ups, and broadcast operations.
Varnish Cache — A web application accelerator that serves as an intermediary between web clients and servers. It provides logging, request inspection, authentication and authorization, and throttling. Varnish can also enhance security as a web application firewall, hotlinking protector, and DDoS attack defense tool.
Squid Caching Proxy — A popular and widely adopted proxy and caching solution for network protocols. It caters for FTP, HTTP, and HTTPS. Squid operates in a similar way to Varnish and optimizes data flow between the client and server. In terms of security, it has authorization, access control, authentication, and support for SSL/TLS. As a bonus, you get activity logs.
NGINX — A popular and consolidated solution for building web applications infrastructure. As an HTTP server, reverse proxy server, and mail proxy server, this solution uses a disk caching method to handle cache. Having a diverse ecosystem for security features, NGINX provides you with HTTP-basic authentication, JWT, and SSL termination. It is also used as a load balancer, application accelerator, and application stack API gateway.
Apache Traffic Server — A free, fast, and scalable HTTP caching system that improves network efficiency. It supports forward and reverse proxy caching and is configurable to run simultaneously on either or both options. It also provides authentication and basic authorization through plugins.
Final Thoughts
In this article, we introduced you to API caching as a way to optimize your web applications. We’ve covered both client-side and server-side caching techniques. We have shown you the best cache implementation practices and informed you of the challenges and considerations you will encounter during the implementation. The choice of caching technique will be narrowed down by various factors like application-specific requirements, performance target metrics, data access patterns, building infrastructure, and memory constraints.
While API caching is a good way to optimize applications, it requires careful planning to balance data freshness, performance gains, and storage costs. When implemented carefully with the right strategy, it could be a game changer for applications handling large volumes of requests. A good caching strategy will include monitoring and fine-tuning the architecture to meet your application's ever-evolving needs. That noted, you can now look at how to build and document a REST API.



